Download it from the Visual Studio Gallery.
Enhancements in Version 3.1
Command-line execution
Run BISM Normalizer from the command line passing the BSMN file as an argument. This allows integration with automated builds.
Syntax
BismNormalizer.exe BsmnFile [/Log:LogFile] [/Script:ScriptFile]
[/Skip:{MissingInSource | MissingInTarget | DifferentDefinitions}]
Arguments
BsmnFile
Full path to the .bsmn file.
/Log:LogFile
All messages are output to LogFile. If the log file already exists, the contents will be replaced.
/Script:ScriptFile
Does not perform actual update to target database; instead, a deployment script is generated and stored to ScriptFile.
/Skip:{MissingInSource | MissingInTarget | DifferentDefinitions}
Skip all objects that are missing in source, missing in target, or with different definitions. This is in addition to the skip actions already defined in the BSMN file.
It is possible to pass a comma-separated list of multiple skip options. For example, “/Skip:MissingInSource,DifferentDefinitions” will skip all objects that are missing in source and those with different definitions.
Automated merging of branches
The /Skip argument can be used for automated merging of branches. For example, by setting /Skip:MissingInSource, it is possible to create/update new/modified objects in a primary branch, without deleting existing ones.
Examples
The following example updates the target database, logging progress and error messages for later review.
BismNormalizer.exe TabularCompare1.bsmn /Log:log.txt
The following example does not update the target database. Instead, a script is generated and progress is logged.
BismNormalizer.exe TabularCompare1.bsmn /Log:log.txt /Script:script.xmla
The following example updates the target database and progress is logged. None of the objects missing in source are deleted.
BismNormalizer.exe TabularCompare1.bsmn /Log:log.txt /Skip:MissingInSource
Passwords and processing
BISM Normalizer in command-line mode does not automatically set passwords for impersonated accounts. They need to be set separately, either manually or securely as part of a build. Processing also needs to be set up separately if required.
Executable location
BISM Normalizer currently only supports standard VSIX deployment from the Visual Studio Gallery. BismNormalizer.exe is located in the extension directory, which looks like “C:\Users\XXX\AppData\Local\Microsoft\VisualStudio\14.0\Extensions\XXX\”, and is shown in the log file produced by the VSIX installer (link available on the installation complete dialog). The executables can be copied to another location using XCOPY deployment.
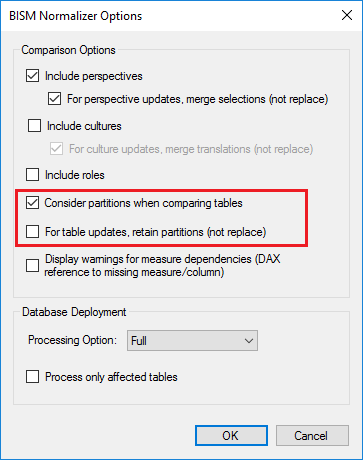
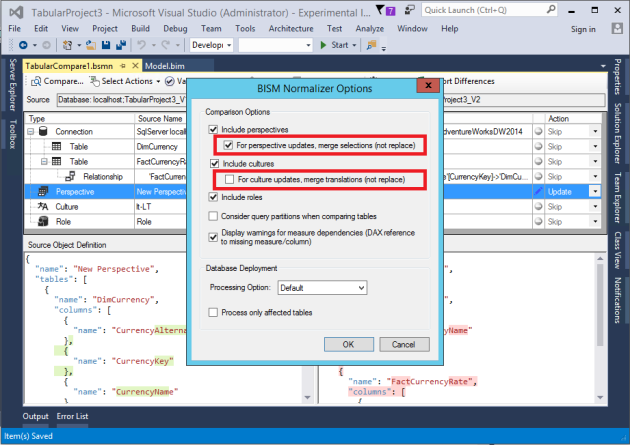
Translations
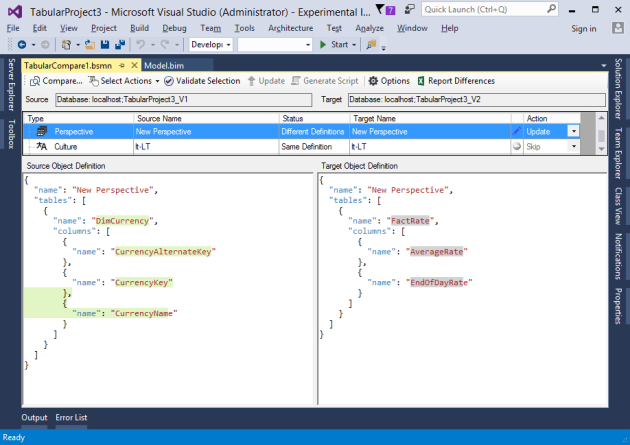
To enable this feature, ensure the include cultures check box is checked.

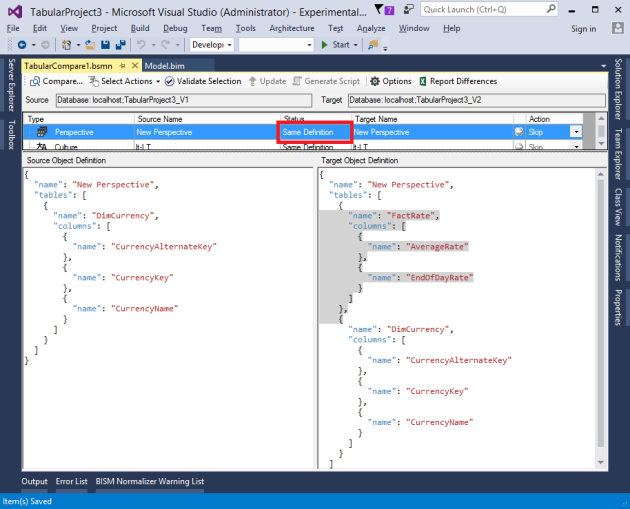
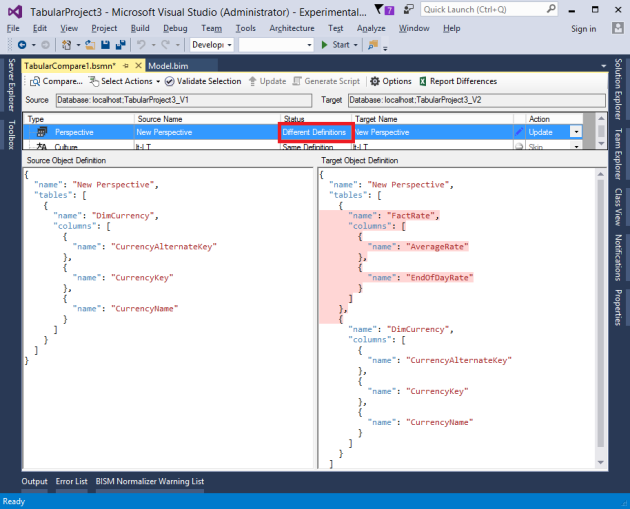
Comparing cultures works similarly to comparing perspectives. Both have a merge option. This allows existing translations in the target culture to be retained. See this post for more info on merging perspectives and translations.
The JSON order of translations in the source/target text boxes is honored from the BIM file/database definition. In some cases they may have different order, but still considered equal since the JSON order doesn’t affect translation functionality.